Hadoop集群搭建-base on Ubuntu18.04
在网上东摘西抄成自己的东西,做个记录,方便以后CV
hadoop是干啥的呢?我就是一句话按我的理解,主要是解决存储和计算的问题,什么存储和计算呢?分布式存储和分布式计算。
这不就是电脑的作用么?一是存储,二是运算。把各种机器的资源利用起来,处理大数据,或者需要大算力的任务。
下载地址:https://hadoop.apache.org/releases.html
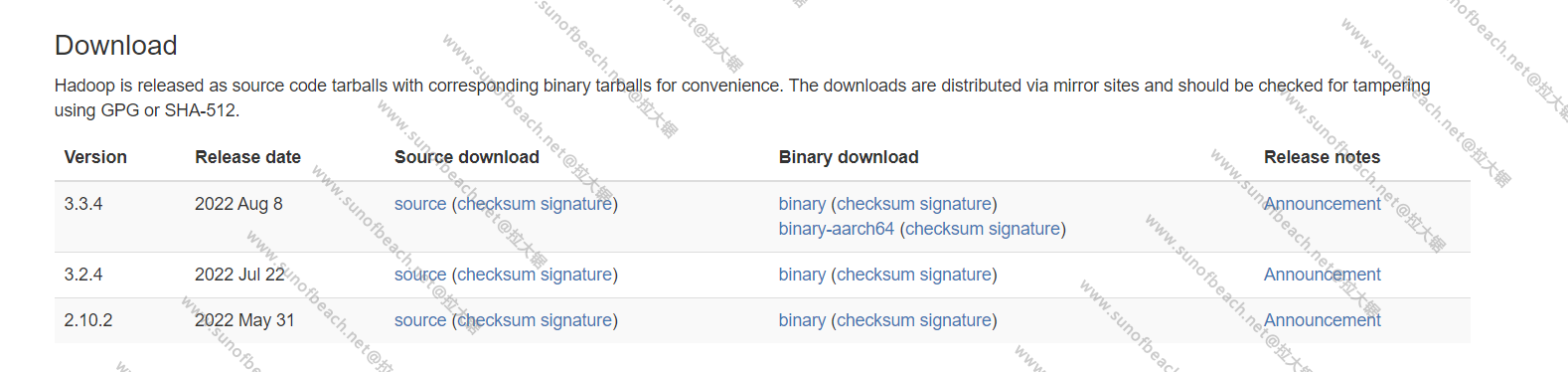
去下载吧!
下载完后上传到服务器上,目录自己定吧,我这里是在opt目录下创建module和package,module就是解压后的模块,package则是存放软件包
解压
tar -zxvf hadoop-3.3.4.tar.gz -C ../module/
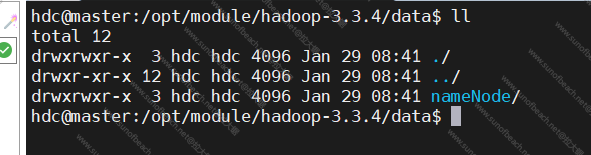
这样子,我就解压到了/opt/module目录下了。
解压以后,得到以上文件列表
okay,到此,文件有了。接下来我们看看这个集群在机器上的规划。
集群规划
这里有准备了三台机器,虚拟机。
ip和hostname: - 192.168.220.100 master - 192.168.220.101 node1 - 192.168.220.102 node2
这个是我以前做集群时祖传的机器,所以命名上有一个master,两个node
相关的进程: - hdfs - namenode - datanode - secondarynamenode - yarn - resourcemanager - nodemanager
规划: - namenode - secondarynamenode - resourcemanager
以上三个是比较耗费资源的,所以打算分三个机器上
datanode则会在每个机器上都跑一个,把数据块存在各个机器上,nodemanager也是跑在各个机器上的。
由以上内容进行配置
集群配置
更多的机器可以按其他的规划。按以上的规划,我们进行配置。
首先,是hdfs的配置,hdfs包括namenode和datanode
namenode会放在第一个机器上,也就是100的机器上
配置java环境
修改文件/opt/module/hadoop-3.3.4/etc/hadoop/hadoop-env.sh,我这里是linux的,所以是.sh的脚本,如果你的是windows的那么就是.cmd的脚本
注意以上的目录,如果你不和我一样放在opt目录下,不要说找不到。
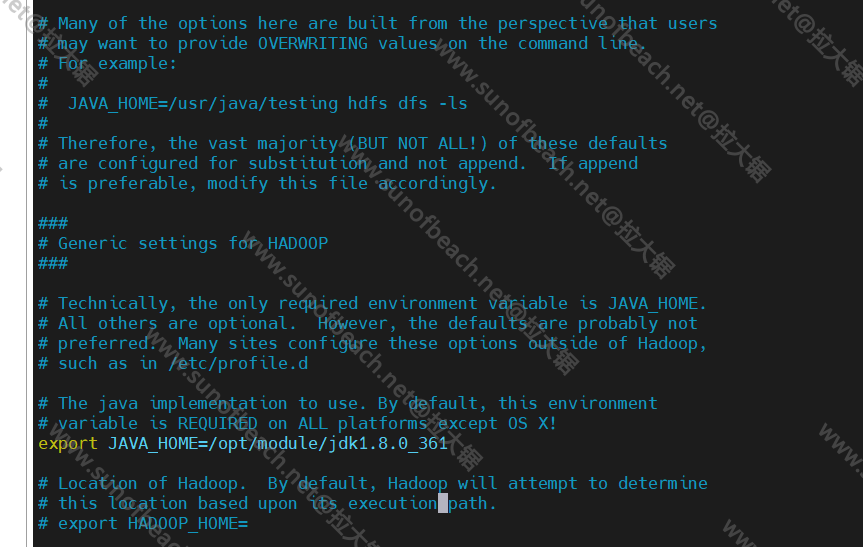
核心配置
配置文件目录/opt/module/hadoop-3.3.4/etc/hadoop/core-site.xml
在configuration节点添加以下配置:
<!--指定namenode的服务器-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.220.100:8020</value>
</property>
<!--自定义的变量,后面在Hdfs文件中引用,存储数据的位置-->
<property>
<name>hadoop.mydata.dir</name>
<value>/opt/module/hadoop-3.3.4/data</value>
</property>
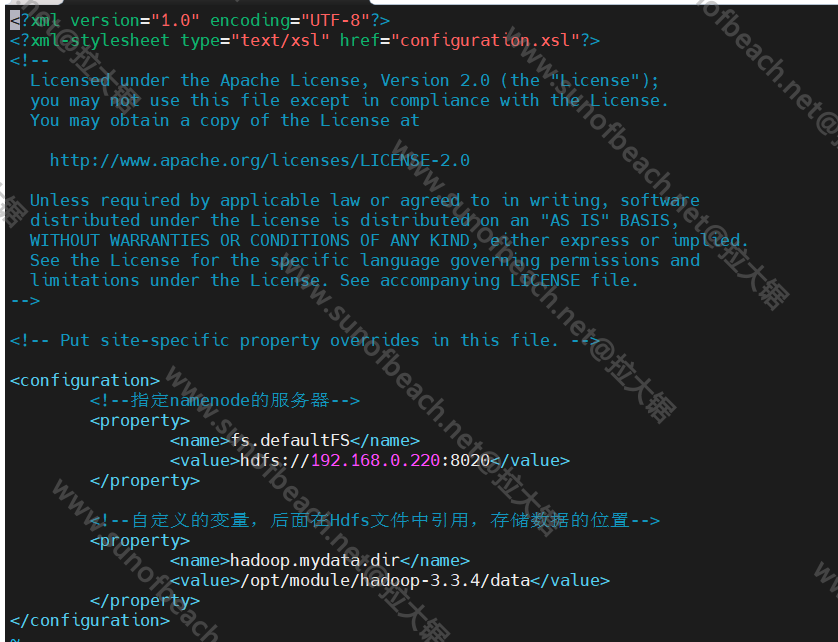
如果这里面配置了hosts,可以直接用hostname来替换ip
hdfs配置
配置文件路径/opt/module/hadoop-3.3.4/etc/hadoop/hdfs-site.xml
添加以下配置:
<!-- 指定SecondaryNameNode的主机和端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.220.102:50090</value>
</property>
<!-- 指定namenode的页面访问地址和端口 -->
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.220.100:50070</value>
</property>
<!-- 指定namenode元数据的存放位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.mydata.dir}/nameNode</value>
</property>
<!-- 定义datanode数据存储的节点位置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.mydata.dir}/dataNode</value>
</property>
<!-- 配置检查点目录 -->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file://${hadoop.mydata.dir}/nameSecondary</value>
</property>
<!-- 文件切片的副本个数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
同样,以上的ip如果你配置了host直接用hostname,我比较懒
那么这些配置项的还有哪些呢?
我们可以看官网嘛
yarn配置
默认配置项
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
修改配置文件/opt/module/hadoop-3.3.4/etc/hadoop/hdfs-yarn.xml,添加以下配置:
<!-- 指定YARN的主角色(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.220.101</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序默认值:"" -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://192.168.220.100:19888/jobhistory/logs</value>
</property>
<!-- 保存的时间7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
配置工作节点
可以通过workers.xml文件配置
192.168.220.100
192.168.220.101
192.168.220.102
我这里就这三个机器
同步配置文件
先同步整个opt下的内容
我分别修改了101和102机器上opt目录的权限
sudo chown hdc:hdc /opt
然后把100的内容同步到101和102上
rsync -a /opt/* hdc@192.168.220.101:/opt
rsync -a /opt/* hdc@192.168.220.102:/opt
以上,包括配置文件都过去了
以后如果我们只修改配置文件,那么就同步一下配置文件即可
单点启动测试
第一次启动格式化namenode
hdfs namenode -format
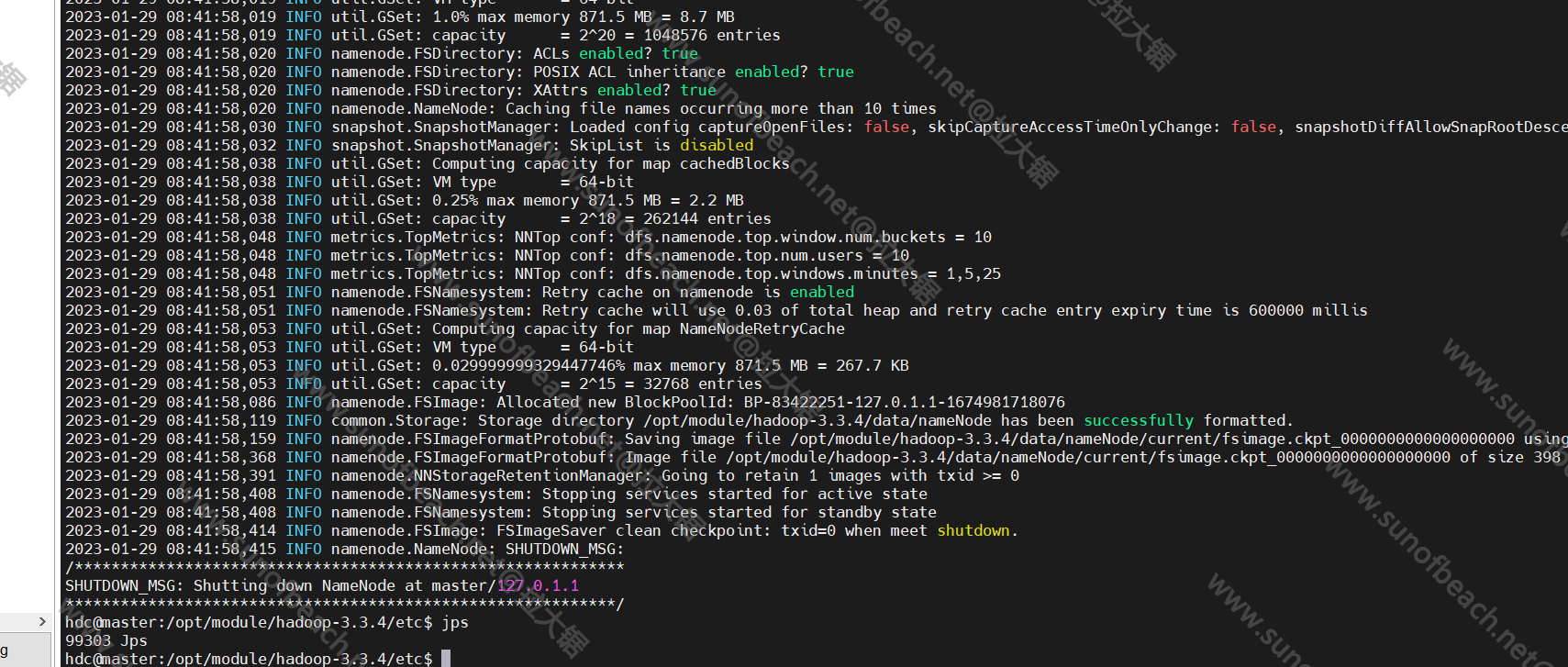
格式化完成
启动namenode
hdfs --daemon start namenode
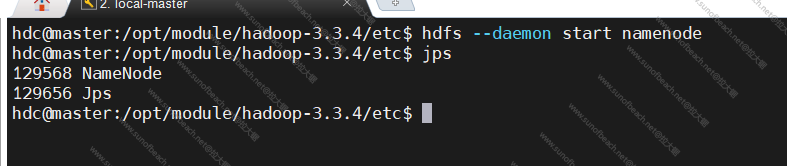
启动成功,jps查看一下
启动datanode

目前我只在单节点上启动,其他节点启动datanode也是一样的,去对应的机器上启动。
secondaryname在102的服务器上启动
hdfs --daemon start secondarynamenode
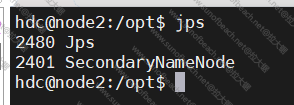
hdfs的启动完了
然后我们启动yarn
yarn的话有resouremanager和nodemanger
按我们前面的规划, 在101机器上跑resourcemanager,在所有机器上跑nodemanager
指令都差不多:
yarn --daemon start resourcemanager
yarn --daemon start nodemanager
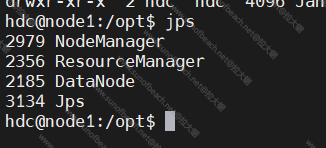
jps脚本
为了查看各个机器上的java进程
我们可以写一个脚本去一次查看
先在home目录下创建一下bin文件夹
在里面写的可执行程序就会在环境变量里了
我们的.profile文件里有把这个路径加入到环境变量中去如果有的话
然后创建文件alljps
内容如下:
#!/bin/bash
echo '==========192.168.220.100========='
jps
echo '==========192.168.220.101========='
ssh 192.168.220.101 /opt/module/jdk1.8.0_361/bin/jps
echo '==========192.168.220.102========='
ssh 192.168.220.102 /opt/module/jdk1.8.0_361/bin/jps
保存退出,修改为可执行文件
chmod +x alljps
调用alljps
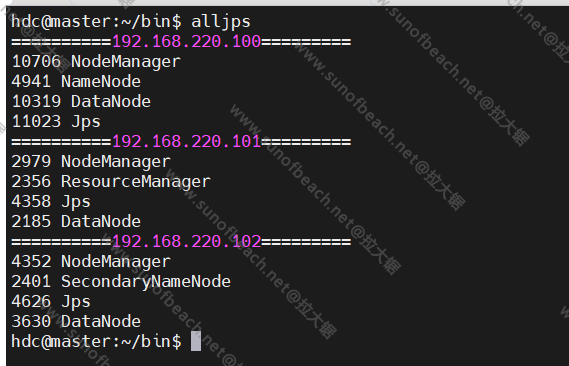
集群启动
前面我个是通过命令一个一个去启动
实际上hadoop已经给我们准备好了脚本,通过脚本我们就可以实现集群的启动。
现在集群没有启动
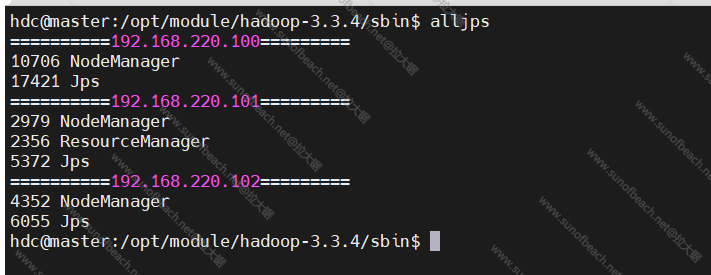
我要开始发动了
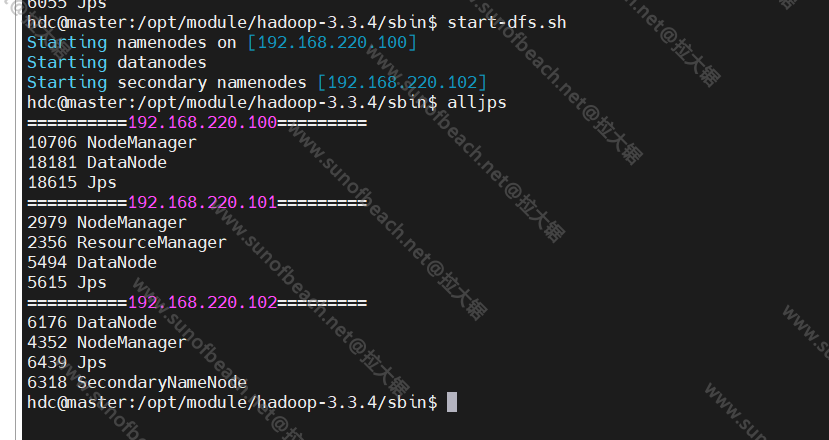
在master的机器上,我们执行:
start-dfs.sh
环境变量我们已经配置过了,这个脚本在hadoop的sbin目录下
好,打完收工,下一篇文章可以要到公司再写咯!
今天元宵节,离过年还有369天!祝大家节日快乐!